
Alibaba Cloud, the digital technology and intelligence backbone of Alibaba Group, recently made its AI models for video generation freely available as part of its latest efforts to contribute to the open-source community.
It is open-sourcing four models of its 14-billion(B)-parameter and 1.3-billion(B)-parameter versions of the Wan2.1 series, the latest iteration of its video foundation model Tongyi Wanxiang (Wan).
The four models, including T2V-14B, T2V-1.3B, I2V-14B-720P, and I2V-14B-480P, are designed to generate high-quality images and videos from text and image inputs. They are available for download on Alibaba Cloud’s AI model community, ModelScope, and the collaborative AI platform Hugging Face, accessible to academics, researchers, and commercial institutions worldwide.
Within a week of their launch, the combined downloads of the four Wan2.1 open-source models on ModelScope and Hugging Face exceeded 1 million.
Unveiled earlier this year, the Wan2.1 series is the first video generation model to support text effects in both Chinese and English. It generates realistic visuals by accurately handling complex movements, enhancing pixel quality, adhering to physical principles, and optimizing the precision of instruction execution.
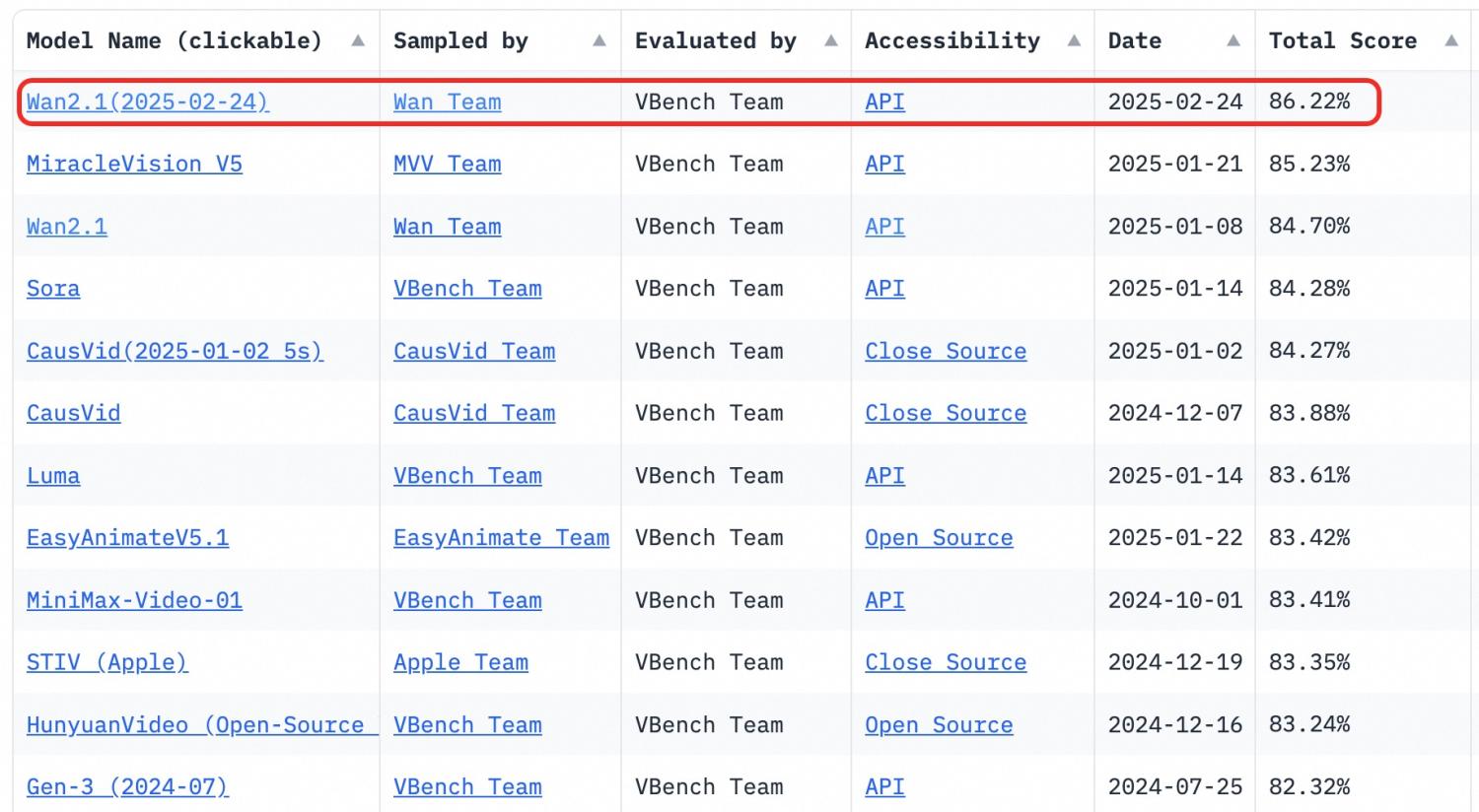
Its precision in following instructions has propelled Wan2.1 to the top of the VBench leaderboard, a comprehensive benchmark suite for video generative models.
According to VBench, the Wan2.1 series, with an overall score of 86.22%, leads in key dimensions such as dynamic degree, spatial relationships, color, and multi-object interactions.
Training video foundation models requires immense computing resources and high-quality training data. Open access helps lower the barrier for more businesses to leverage AI, enabling them to create high-quality visual content tailored to their needs cost-effectively.
You can view the sample video here. Text prompt: “In a wide-angle, frontal shot, a man dives from the platform in red swim trunks, arms out and legs together. As the camera lowers, he leaps into the water, creating splashes, with the blue pool in the background.”
The T2V-14B model is better suited for creating high-quality visuals with substantial motion dynamics. In contrast, the T2V-1.3B model balances generation quality and computational power, making it ideal for various developers conducting secondary development and academic research. For example, the T2V-1.3B model allows users with standard personal laptops to generate a 5-second-long video at 480p resolution in at least 4 minutes.
The I2V-14B-720P and I2V-14B-480P models support text-to-video generation and offer image-to-video capabilities. To generate dynamic video content, users simply need to input a single image along with a brief text description. The platform supports normal-sized image inputs of any dimension.
Alibaba Cloud was one of the first major global tech companies to open-source its self-developed large-scale AI model, releasing its first open-model, Qwen (Qwen-7B), in August 2023. Qwen open models have consistently topped the Hugging Face Open LLM Leaderboards, with performances matching those of leading global AI models across various benchmarks.
More than 100,000 derivative models based on the Qwen family of models have been developed on Hugging Face, making it one of the most prominent AI model families worldwide.